In October 2020, Chrome enabled HTTP/3 by default. HTTP/3 (RFC 9114) runs over IETF QUIC (RFC9000). Default-enabling HTTP/3 in Chrome resulted in improved performance compared not only HTTP/1 and HTTP/2, but also Google QUIC. Benefits included reduced Google search latency and fewer rebuffers for YouTube.
The journey to optimizing performance did not end when HTTP/3 was default enabled. Recent advancements include the implementation of the HTTP/3 ORIGIN frame (RFC 9412) and Server's Preferred Address (RFC 9000 Section 9.6). The former enhances connection coalescing, while the latter reduces a connection's round trip time (RTT). Both features have been enabled by default in M131, which was released to Stable on 11/19.
When a connection is established for a specific hostname, the server’s certificate typically contains numerous other hostnames for which the server is authoritative. However, a client cannot immediately send requests for those other hostnames on that connection without first performing a DNS lookup for the other hostname and verifying that the IP address of the connection matches the resolved address. This additional DNS resolution introduces latency and significantly reduces the likelihood of connection pooling due to potential IP mismatches. The metrics from Chrome indicate that nearly 20% of HTTP/3 connections would be unnecessary if not for this IP mismatch.
Creating a new connection, even with QUIC 0-RTT, is expensive in terms of latency, memory, and CPU usage. This is because:
Additionally, features like HTTP priorities (RFC 9218) are only effective if there are multiple simultaneous responses to send.
The HTTP/3 ORIGIN Frame (RFC 9412) enables a server to indicate what domains it would like to pool onto a connection. Additionally, once the frame is received, it indicates other domains should not be pooled onto that connection, even if they are in the certificate.
In some cases, the initial server address to which the client connects is not the most efficient route. It might be behind an L4 load balancer, and connecting directly could increase stability. Particularly when using Anycast, it’s possible the server is distant from where traffic enters the network, creating a 3-legged path that increases the round trip time.
Once the handshake is confirmed, Server’s Preferred Address allows a server to indicate it would like the client to migrate to a different server IP. Though a QUIC connection is not bound to a single 4-tuple like TCP, this is the only type of migration in RFC9000 where the server can change its address.
So far, only Google’s Media CDN has widely enabled advertising an alternative address, but we expect more servers to adopt it soon. Testing has shown that this migration is successful over 99% of the time in Chrome and reduces average RTT by 40-80%.
Today’s The Fast and the Curious post covers how Chrome achieved best-in-class Speedometer scores on mobile devices, resulting in faster and smoother web experiences for Android users.
Chrome has always been about speed. Whether it's loading pages quickly, running complex web apps smoothly, or delivering a seamless browsing experience, performance is at the heart of our browser. And we're always looking for ways to make Chrome even faster.
Over the last two years, we have been hard at work on a number of performance improvements for Android devices. We're excited to share some of the progress we've made.
One of the key metrics we use to track Chrome's performance is the Speedometer benchmark. This benchmark is developed in collaboration with other major web browser engines and measures how quickly Chrome can complete interactions with web pages, including parsing/rendering HTML or CSS and running JavaScript.
Since the release of Chrome M112, we've seen a significant increase in Speedometer 2.1 scores on Android devices [1]. In fact, on many devices, scores more than doubled, with the newest Snapdragon® 8 Elite Mobile Platform setting new records for Speedometer performance on mobile devices! These huge accomplishments are a testament to the work not only of the Chrome and Android teams, but also our silicon and SoC partners.
Since Chrome M112, Speedometer 2.1 scores have more than doubled on many Android devices. [1]
The improvements resulted from several changes, including:
Let's take a closer look at each of these areas.
The Android device ecosystem is very diverse. From entry-level phones to the newest premium ones, Chrome needs to run well on all devices. Up until last year, we shipped the same Chrome build to all these different Android devices. The memory and disk size constraints on entry-level devices resulted in Chrome having to prioritize a small binary size. Consequently, many modern build optimizations were out of reach, as they resulted in much larger binaries.
With M113, Chrome was finally able to ship a separate higher-performance build targeting premium Android devices via the Google Play Store. While we still ship a more binary-size-constrained build to other devices, this approach allowed us to land some of those modern optimizations into the new premium build:
Together, these build optimizations account for more than half of the overall Speedometer score improvements. This progress was facilitated by our collaboration with Arm, who contributed valuable insights and improvements, including to identify and address inefficiencies in Chrome's PGO setup and inlining.
Chrome continuously improves the performance of its JavaScript and web rendering engines, V8 and Blink. Most optimizations are small in individual impact, but stacked together, these improvements add up and contributed most of the remaining Speedometer impact! Notable ones include:
To achieve the best possible performance, Android partners invest heavily in tuning the operating system's thread scheduling and frequency scaling policies, as well as improving the performance of the Silicon itself.
We worked closely with our partners to improve their tuning for Chrome and Speedometer. In particular, our collaboration with Qualcomm was very fruitful: By combining optimized scheduling policies with improved hardware performance, their newest Snapdragon 8 Elite mobile platform realized a 60-80% improvement in Speedometer 3.0 compared to its predecessor, resulting in class-leading web performance. This collaboration also highlighted important bottlenecks in Chrome's code, such as the need for improved PGO and opportunities in V8.
Speedometer 3.0 on Snapdragon 8 Gen 3 (left) compared to Snapdragon 8 Elite (right), Chrome M131
Faster Speedometer scores translate to improvements in real user interactions with web content, such as faster page loads and interactions. Back at M112, loading a Google Docs document on Pixel Tablet took more than 50% longer than it does today -- that's the effect of a doubled Speedometer score!
Chrome M112 vs. M129 on Pixel Tablet, loading a Google Doc (frame count)
[1] Speedometer 3 was released during M122, so results from Speedometer 2.1 are provided for a full picture. Measurements shown in graphs were taken on Pixel Tablet.
Last October, we introduced a new identity model on iOS (Chrome 118) and are excited to bring it to Android devices and Desktop soon. This model aligns closely with how you already use other Google apps and services.
When we first launched Chrome sync back in 2009, powered by the Google Account, our goal then, as it is today, was simple: help users access their bookmarks, passwords, tabs and more, across devices. At the time, this was best achieved by a sync model: synchronizing device data with your account and therefore requiring both sign-in and enabling sync.
Over the years, the digital world has changed and user expectations have evolved significantly. Cloud services emerged in 2010, and over the past 15 years, the concept of having a digital identity became more prevalent, especially through smartphones and mobile apps. Today, users increasingly expect to just sign in to get access to their stuff and sign out to keep it safe.
Given this evolution of technology and user norms, we’re continuing to make progress on transforming our legacy sync model into one that more seamlessly meets the expectation users have today. From the point of signing in to Chrome you’ll get access to your saved passwords, addresses, and other data from your Google Account. Where relevant, we’ll offer you the choice to sign into Chrome for a customized browsing experience on any device. For example, you can sign in and start to plan a trip on your phone during your commute, and then seamlessly finish it up on any device. Send tabs between your devices, find your bookmarks and use autogenerated passwords with ease.
As always, you have control - we strive to provide an excellent browser experience regardless of whether you choose to sign in or not. Additionally, saving your history and open tabs to your account remains a separate opt-in after signing into Chrome.
Stay tuned for updates on this change - already on iOS and coming to Android and Desktop soon.
ChromeOS will soon be developed on large portions of the Android stack to bring Google AI, innovations, and features faster to users.
Over the last 13 years, we’ve evolved ChromeOS to deliver a secure, fast, and feature-rich Chromebook experience for millions of students and teachers, families, gamers, and businesses all over the world. With our recent announcements around new features powered by Google AI and Gemini, Chromebooks now give us the opportunity to put powerful tools in the hands of more people to help with everyday tasks.
To continue rolling out new Google AI features to users at a faster and even larger scale, we’ll be embracing portions of the Android stack, like the Android Linux kernel and Android frameworks, as part of the foundation of ChromeOS. We already have a strong history of collaboration, with Android apps available on ChromeOS and the start of unifying our Bluetooth stacks as of ChromeOS 122.
Bringing the Android-based tech stack into ChromeOS will allow us to accelerate the pace of AI innovation at the core of ChromeOS, simplify engineering efforts, and help different devices like phones and accessories work better together with Chromebooks. At the same time, we will continue to deliver the unmatched security, consistent look and feel, and extensive management capabilities that ChromeOS users, enterprises, and schools love.
These improvements in the tech stack are starting now but won’t be ready for consumers for quite some time. When they are, we’ll provide a seamless transition to the updated experience. In the meantime, we continue to be extremely excited about our continued progress on ChromeOS without any change to our regular software updates and new innovations.
Chromebooks will continue to deliver a great experience for our millions of customers, users, developers and partners worldwide. We’ve never been more excited about the future of ChromeOS.
Posted by Prajakta Gudadhe, Senior Director, Engineering, ChromeOS & Alexander Kuscher, Senior Director, Product Management, ChromeOS
Today’s The Fast and the Curious post explores how Chrome achieved the highest score on the new Speedometer 3.0, an upgraded browser benchmarking tool to optimize the performance of Web applications. Try out Chrome today!
Speedometer 3.0 is a recently published benchmark for measuring browser performance that was created as an industry collaboration between companies like Google, Apple, Mozilla, Intel, and Microsoft. This benchmark helped us identify areas in which we could optimize Chrome to deliver a faster browser experience to all our users.
Here’s a closer look at how we further optimized Chrome to achieve the highest score ever Speedometer 3, by carefully tracking its recent performance over time as the updated benchmark was being developed. Since the inception of Speedometer 3 in May 2022, we've driven a 72% increase in Chrome’s Speedometer score - translating into performance gains for our users:
By looking at the workloads in Speedometer and in which functions Chrome was spending the most time, we were able to make targeted optimizations to those functions that each drove an increase in Chrome’s score. For example, the SpaceSplitString function is used heavily to turn space-separated strings such as those in “class=’foo bar’ ” into a list representation. In this function we removed some unnecessary bound checks. When we detect that there are duplicated stylesheets, we dedupe them and reference a single stylesheet instance. We made an optimization to reduce the cost of drawing paths and arcs by tuning memory allocations. When creating form editors we detected some unnecessary processing that occurs when form elements are created. Within querySelector, we were able to detect what selector was commonly used and create a hot-path for that.
We previously shared how we optimized innerHTML using specialized fast paths for parsing, an implementation that also made its way into WebKit. Some workloads in Speedometer 3 use DOMParser so we extended the same optimization for another 1% gain.
We worked with the Harfbuzz maintainer to also optimize how Chrome renders AAT fonts such as those used by Apple Mac OS system fonts. Text starts as a processed stream of unicode characters that is then transformed into a glyph stream that is then run through a state machine defined in the AAT font. The optimization allows us to determine more quickly whether glyphs actually participate in the rules for the state machine, leading to speed-ups when processing text using AAT.
An important strategy for achieving high performance is tiering up code, which is picking the right code to further optimize within the engine. Intel contributed profile guided tiering to V8 that remembers tiering decisions from the past such that if a function was stably tiered up in the past, we eagerly tier it up on future runs.
Another area of changes that drove around 3% progression on Speedometer 3 was improvements around garbage collection. V8’s garbage collector has a long history of making use of renderer idle time to avoid interfering with actual application code. The recent changes follow this spirit by extending existing mechanisms to prefer garbage collection in idle time on otherwise very active renderers where possible. Specifically, DOM finalization code that is run on reclaiming objects is now also run in idle time. Previously, such operations would compete with regular application code over CPU resources. In addition, V8 now supports a much more compact layout for objects that wrap DOM elements, i.e., all objects that are exposed to JavaScript frameworks. The compact layout reduces memory pressure and results in less time spent on garbage collection.
Posted by Thomas Nattestad, Chrome Product Manager
On the Chrome team, we believe it’s not sufficient to be fast most of the time, we have to be fast all of the time. Today’s The Fast and the Curious post explores how we contributed to Core Web Vitals by surveying the field data of Chrome responding to user interactions across all websites, ultimately improving performance of the web.
As billions of people turn to the web to get things done every day, the browser becomes more responsible for hosting a multitude of apps at once, resource contention becomes a challenge. The multi-process Chrome browser contends for multiple resources: CPU and memory of course, but also its own queues of work between its internal services (in this article, the network service).
This is why we’ve been focused on identifying and fixing slow interactions from Chrome users’ field data, which is the authoritative source when it comes to real user experiences. We gather this field data by recording anonymized Perfetto traces on Chrome Canary, and report them using a privacy-preserving filter.
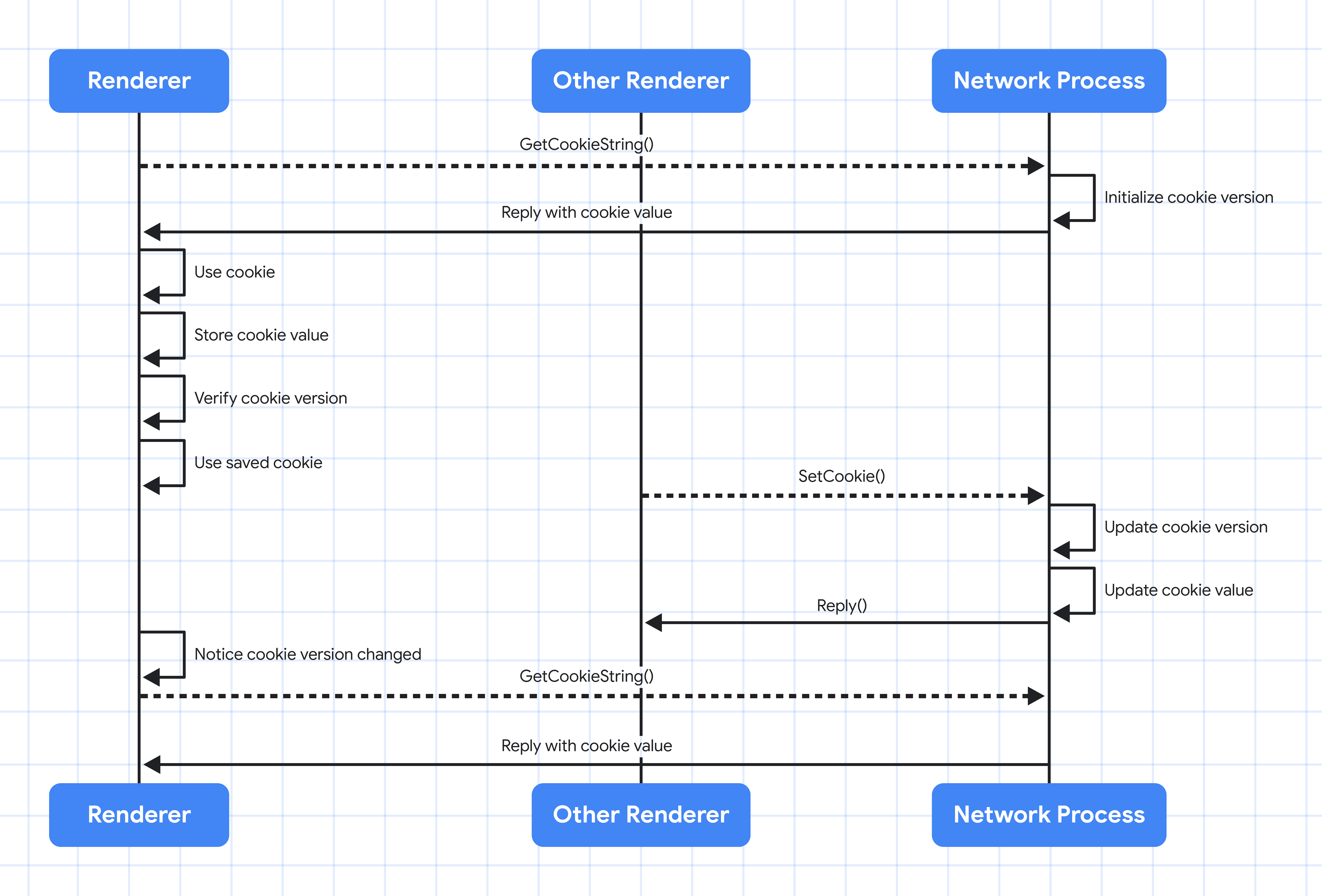
When looking at field data of slow interactions, one particular cause caught our attention: recurring synchronous calls to fetch the current site’s cookies from the network service.
Let’s dive into some history.
Cookies have been part of the web platform since the very beginning. They are commonly created like this:
document.cookie = "user=Alice;color=blue"
And later retrieved like this:
// Assuming a `getCookie` helper method: getCookie("user", document.cookie)
Its implementation was simple in single-process browsers, which kept the cookie jar in memory.
Over time, browsers became multi-process, and the process hosting the cookie jar became responsible for answering more and more queries. Because the Web Spec requires Javascript to fetch cookies synchronously, however, answering each document.cookie query is a blocking operation.
document.cookie
The operation itself is very fast, so this approach was generally fine, but under heavy load scenarios where multiple websites are requesting cookies (and other resources) from the network service, the queue of requests could get backed up.
We discovered through field traces of slow interactions that some websites were triggering inefficient scenarios with cookies being fetched multiple times in a row. We landed additional metrics to measure how often a GetCookieString() IPC was redundant (same value returned as last time) across all navigations. We were astonished to discover that 87% of cookie accesses were redundant and that, in some cases, this could happen hundreds of times per second.
GetCookieString()
The simple design of document.cookie was backfiring as JavaScript on the web was using it like a local value when it was really a remote lookup. Was this a classic computer science case of caching?! Not so fast!
The web spec allows collaborating domains to modify each other’s cookies. Hence, a simple cache per renderer process didn’t work, as it would have prevented writes from propagating between such sites (causing stale cookies and, for example, unsynchronized carts in ecommerce applications).
We solved this with a new paradigm which we called Shared Memory Versioning. The idea is that each value of document.cookie is now paired with a monotonically increasing version. Each renderer caches its last read of document.cookie alongside that version. The network service hosts the version of each document.cookie in shared memory. Renderers can thus tell whether they have the latest version without having to send an inter-process query to the network service.
This reduced cookie-related inter-process messages by 80% and made document.cookie accesses 60% faster 🥳.
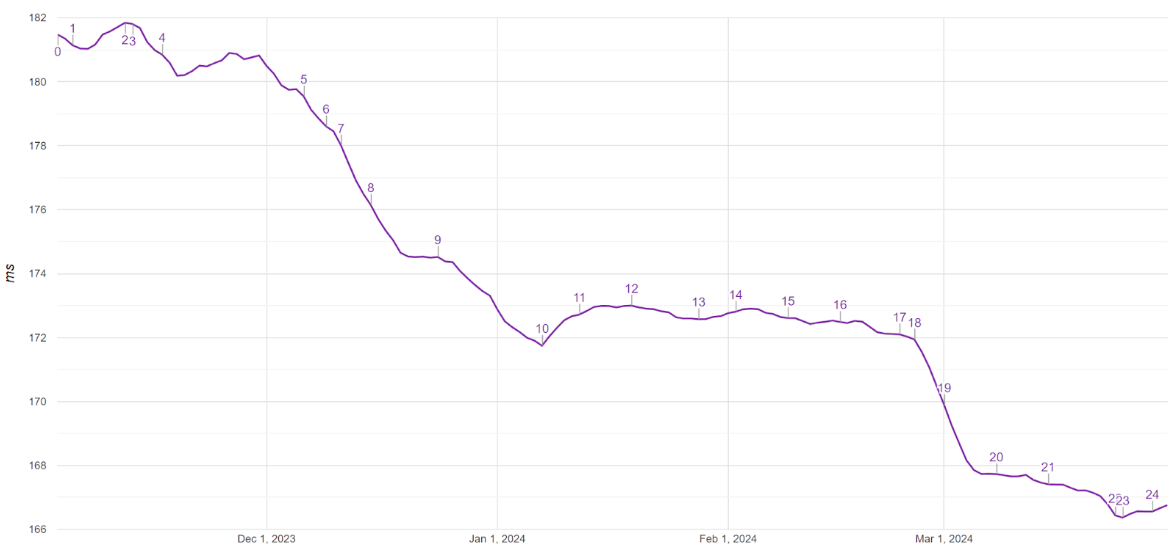
Improving an algorithm is nice, but what we ultimately care about is whether that improvement results in improving slow interactions for users. In other words, we need to test the hypothesis that stalled cookie queries were a significant cause of slow interactions.
To achieve this, we used Chrome’s A/B testing framework to study the effect and determined that it, combined with other improvements to reduce resource contention, improved the slowest interactions by approximately 5% on all platforms. This further resulted in more websites passing Core Web Vitals 🥳. All of this adds up to a more seamless web for users.
Timeline of the weighted average of the slowest interactions across the web on Chrome as this was released to 1% (Nov), 50% (Dec), and then all users (Feb).
By Gabriel Charette, Olivier Li Shing Tat-Dupuis, Carlos Caballero Grolimund, and François Doray, from the Chrome engineering team
In November 2023, we shared a timeline for the phasing out of Manifest V2 extensions in Chrome. Based on the progress and feedback we’ve seen from the community, we’re now ready to roll out these changes as scheduled.
We’ve always been clear that the goal of Manifest V3 is to protect existing functionality while improving the security, privacy, performance and trustworthiness of the extension ecosystem as a whole. We appreciate the collaboration and feedback from the community that has allowed us - and continues to allow us - to constantly improve the extensions platform.
Addressing community feedback
We understand migrations of this magnitude can be challenging, which is why we’ve listened to developer feedback and spent years refining Manifest V3 to support the innovation happening across the extensions community. This included adding support for user scripts and introducing offscreen documents to allow extensions to use DOM APIs from a background context. Based on input from the extension community, we also increased the number of rulesets for declarativeNetRequest, allowing extensions to bundle up to 330,000 static rules and dynamically add a further 30,000. You can find more detail in our content filtering guide.
This month, we made the transition even easier for extensions using declarativeNetRequest with the launch of review skipping for safe rule updates. If the only changes are for safe modifications to an extension’s static rule list for declarativeNetRequest, Chrome will approve the update in minutes. Coupled with the launch of version roll back last month, developers now have greater control over how their updates are deployed.
Ecosystem progress
After we addressed the top issues and feature gaps blocking migration last year, we saw an acceleration of extensions migrating successfully to Manifest V3. Over the past year, we’ve even been able to invite some developers - such as Eyeo, the makers of Adblock Plus - and GDE members like Matt Frisbie to share their experiences and insights with the community through guest posts and YouTube videos.
Now, over 85% of actively maintained extensions in the Chrome Web Store are running Manifest V3, and the top content filtering extensions all have Manifest V3 versions available - with options for users of AdBlock, Adblock Plus, uBlock Origin and AdGuard.
What to expect next
Starting on June 3 on the Chrome Beta, Dev and Canary channels, if users still have Manifest V2 extensions installed, some will start to see a warning banner when visiting their extension management page - chrome://extensions - informing them that some (Manifest V2) extensions they have installed will soon no longer be supported. At the same time, extensions with the Featured badge that are still using Manifest V2 will lose their badge.
This will be followed gradually in the coming months by the disabling of those extensions. Users will be directed to the Chrome Web Store, where they will be recommended Manifest V3 alternatives for their disabled extension. For a short time after the extensions are disabled, users will still be able to turn their Manifest V2 extensions back on, but over time, this toggle will go away as well.
Like any big launches, all these changes will begin in pre-stable channel builds of Chrome first – Chrome Beta, Dev, and Canary. The changes will be rolled out over the coming months to Chrome Stable, with the goal of completing the transition by the beginning of next year. Enterprises using the ExtensionManifestV2Availability policy will be exempt from any browser changes until June 2025.
We’ve shared more information about the process in our recent Chrome extensions Google I/O talk. If you have any additional questions, don’t hesitate to reach out via the Chromium extensions mailing list.
In the latest release of Chrome, we're introducing Minimized Custom Tabs, a feature that allows users to effortlessly transition between native app and web content. With a simple tap on the down button in the Chrome Custom Tabs toolbar, users can minimize a Custom Tab into a compact, floating picture-in-picture window. This seamless integration enables multi-tasking across surfaces, enhancing the in-app web browsing experience. By tapping on the floating window, users can easily maximize the tab, restoring it to its original size.
Because this change happens at the browser level, developers who use Chrome Custom Tabs will see this change automatically applied starting with Chrome version M124. End users will see the Minimize icon in the Chrome Custom Tab toolbar.
Please note that this is a change in Chrome, and we hope other browsers will adopt similar functionality.
Posted by Victor Gallet, Senior Product Manager
Google and many other organizations, such as NIST, IETF, and NSA, believe that migrating to post-quantum cryptography is important due to the large risk posed by a cryptographically-relevant quantum computer (CRQC). In August, we posted about how Chrome Security is working to protect users from the risk of future quantum computers by leveraging a new form of hybrid post-quantum cryptographic key exchange, Kyber (ML-KEM)1. We’re happy to announce that we have enabled the latest Kyber draft specification by default for TLS 1.3 and QUIC on all desktop Chrome platforms as of Chrome 124.2 This rollout revealed a number of previously-existing bugs in several TLS middlebox products. To assist with the deployment of fixes, Chrome is offering a temporary enterprise policy to opt-out.
Launching opportunistic quantum-resistant key exchange is part of Google’s broader strategy to prioritize deploying post-quantum cryptography in systems today that are at risk if an adversary has access to a quantum computer in the future. We believe that it’s important to inform standards with real-world experience, by implementing drafts and iterating based on feedback from implementers and early adopters. This iterative approach was a key part of developing QUIC and TLS 1.3. It’s part of why we’re launching this draft version of Kyber, and it informs our future plans for post-quantum cryptography.
Chrome’s post-quantum strategy prioritizes quantum-resistant key exchange in HTTPS, and increased agility in certificates from the Web PKI. While PKI agility may appear somewhat unrelated, its absence has contributed to significant delays in past cryptographic transitions and will continue to do so until we find a viable solution in this space. A more agile Web PKI is required to enable a secure and reliable transition to post-quantum cryptography on the web.
To understand this, let’s take a look at HTTPS and the current state of post-quantum cryptography. In the context of HTTPS, cryptography is primarily used in three different ways:
This results in two separate quantum threats to HTTPS.
The first is the threat to traffic being generated today. An adversary could store encrypted traffic now, wait for a CRQC to be practical, and then use it to decrypt the traffic after the fact. This is commonly known as a store-now-decrypt-later attack. This threat is relatively urgent, since it doesn’t matter when a CRQC is practical—the threat comes from storing encrypted data now. Defending against this attack requires the key exchange to be quantum resistant. Launching Kyber in Chrome enables servers to mitigate store-now-decrypt-later attacks.
The second threat is that future traffic is vulnerable to impersonation by a quantum computer. Once a CRQC actually exists, it could be used to break the asymmetric cryptography used for authentication in HTTPS. To defend against impersonation from a CRQC, we need to migrate all of the asymmetric cryptography used for authentication to post-quantum variants. However, breaking authentication only affects traffic generated after the availability of CRQCs. This is because breaking authentication on a recorded transcript doesn’t help the attacker impersonate either party—the conversation has already finished.
In other words, there’s no store-now-decrypt-later equivalent for authentication, and so while migrating key exchange and authentication to post-quantum variants are both important, migrating authentication is less urgent than key exchange. This is good, because there are a variety of challenges for migrating to post-quantum authentication. Specifically, size.
Post-quantum cryptography is big compared to the pre-quantum cryptographic algorithms used in HTTPS. A Kyber key exchange is ~1KB transmitted per peer, whereas an X25519 key exchange is only 32 bytes per peer, an over 30x increase. The actual key exchange operation in Kyber is quite fast. Transmitting Kyber keys is quite slow. The extra size from Kyber causes the TLS ClientHello to be split into two packets, resulting in a 4% median latency increase to all TLS handshakes in Chrome on desktop. On desktop platforms, this, with HTTP/2 and HTTP/3 connection reuse, is not large enough to be noticeable in Core Web Vitals. Unfortunately, it is noticeable on Android, where Internet connections are often lower bandwidth and higher latency, and so we have not yet launched on Android.
The size issues are even worse for authentication. ML-DSA (Dilithium) keys and signatures are ~40X the size of ECDSA keys and signatures. A typical TLS connection today uses two public keys and five signatures to fulfill all of the authentication requirements. A naive swap to ML-DSA would add ~14KB to the TLS handshake. Cloudflare anticipates it would increase latency by 20-40%, and we’ve seen that a single kilobyte was already impactful. Instead, we need alternate approaches to authentication in HTTPS that provide the desired properties and transmit fewer signatures and public keys.
We think the important next step for quantum-resistant authentication in HTTPS is to focus on enabling trust anchor agility. Historically, the public Web PKI could not deploy new algorithms quickly. This is because most site operators typically provision a single certificate for all supported clients and browsers. This certificate must both be issued from a trust hierarchy that is trusted by every browser or client the site operator supports, and the certificate must be compatible with each of these clients.
The single certificate model makes it difficult for the Web PKI to evolve. As security requirements change, site operators may find that there is no longer an intersection between certificates trusted by deployed clients, certificates trusted by new clients, algorithms supported by deployed clients, and algorithms supported by new clients (all crossed with every separate browser and root store). These clients may range from different browsers, older versions of those browsers not receiving updates, all the way to applications on smart TVs or payment terminals. As requirements diverge, site operators have to choose between security for new clients, and compatibility with older clients.
This conflict, in turn, limits new clients making PKI changes to improve user security, such as transitioning to post-quantum. Under a single-certificate deployment model, the newest clients cannot diverge too far from the oldest clients, or server operators will be left with no way to maintain compatibility. We propose to solve this by moving to a multi-certificate deployment model, where servers may be provisioned with multiple certificates, and automatically send the correct one to each client. This enables trust anchor agility, and allows clients to evolve at different rates. Clients who are up to date and reliably receiving updates could access the authentication mechanisms best suited for the Internet as it evolves without being hamstrung by old clients no longer receiving updates. Certification authorities and trust stores could introduce new post-quantum trust anchors without needing to wait for the slowest actor to add support. This would drastically simplify the post-quantum transition since it also enables the seamless addition and removal of hierarchies using experimental post-quantum authentication methods.
At first glance, TLS may appear to have trust anchor agility by way of cross-signatures and signature algorithm negotiation. However, neither of these mechanisms provide true trust anchor agility, nor were they intended to.
A cross-signature is when a CA creates two different certificates for a single subject and public key pair, but with different issuers and signatures. The first certificate is issued and signed as usual, by the CA itself. The second is issued and signed by a different trust hierarchy, often by a different organization. For example, the original Let’s Encrypt intermediate certificate existed in two forms3. The “regular” intermediate was signed by the Let’s Encrypt root, whereas the “cross-signed” intermediate was signed by IdenTrust. This approach of cross-signing a new PKI hierarchy with an older, more broadly available PKI hierarchy allows a new CA to bootstrap its trust on old devices, so long as the older devices support the signing algorithm. Cross-signatures, however, rely on significant cooperation among often competing CAs, and may not be suitable for when different clients have different needs. This limits when site operators can use cross-signs. Additionally, devices that do not support a new algorithm will still need to be updated to be able to use the new signing algorithm in the newer certificate, regardless of whether or not it is cross-signed.
Signature algorithm negotiation allows TLS peers to agree on the algorithm to be used for the handshake signature. This algorithm needs to correspond with the key type used in the certificate. Endpoints can infer that if the peer supports an algorithm such as ECDSA for the handshake signature, it must also support ECDSA certificates. This value can be used to multiplex between an RSA-based chain and a smaller ECDSA-based chain. For example, Google’s RSA-based large compatibility chain is four certificates and ~4.1KB, whereas the shortest ECDSA-based chain is three certificates and only ~1.7KB4.
Signature algorithm negotiation does not provide trust anchor agility. While the signature algorithm information implies algorithm support, it provides no information about what trust anchors a client actually trusts. A client can support ECDSA, but not have the latest ECDSA root certificate from a specific CA. Due to the wide variety of trust stores in use, many organizations may still often need to be conservative in when they serve ECDSA certificates and may need to provide a longer, cross-signed chain for maximum compatibility.
Neither cross-signatures nor signature algorithm negotiation are solutions to migrating to post-quantum cryptography for authentication. Cross-signatures do not help with new algorithms, and signature algorithm negotiation is solely about negotiating algorithms, not providing information about trust anchors. We expect a gradual transition to post-quantum cryptography. Inferring information about the contents of the trust store from the result of signature algorithm negotiation risks ossifying to a specific version of a specific trust store, rather than purely being used for algorithm negotiation.
Instead, to introduce agility to TLS we need an explicit mechanism for trust anchor negotiation, to allow the client and server to efficiently determine which certificate to use. At the November 2023 IETF meeting in Prague, Chrome proposed “Trust Expressions” as a mechanism for trust anchor negotiation in TLS. Chrome is currently seeking community input on Trust Expressions via the IETF process. We think the goal of being able to cleanly deploy multiple certificates to handle a range of clients is much more important than the specific mechanisms of the proposal.
From there, we can explore more efficient ways to authenticate servers, such as Merkle Tree Certificates. We view introducing some mechanism for trust anchor agility as a necessity for efficient post-quantum authentication. Experimentation will be extremely important as proposals are developed. Agility also enables using different solutions in different contexts, rather than sending extra data for the lowest-common denominator— solutions like Merkle Tree Certificates and intermediate elision require up-to-date clients.
Given these constraints, priorities, and risks, we think agility is more important than defining exactly what a post-quantum PKI will look like at this time. We recommend against immediately standardizing ML-DSA in X.509 for use in the public Web PKI via the CA/Browser Forum. We expect that ML-DSA, once NIST completes standardization, will play a part in a post-quantum Web PKI, but we’re focusing on agility first. This does not preclude introducing ML-DSA in X.509 as an option for private PKIs, which may be operating on more strict post-quantum timelines and have fewer constraints around certificate size, handshake latency, issuance transparency, and unmanaged endpoints.
Ultimately, we think that any approach to post-quantum authentication has the same first requirement—a migration mechanism for clients to opt-in to post-quantum secure authentication mechanisms when servers support it. Post-quantum authentication presents significant challenges to the Web ecosystem, but we believe trust anchor agility will enable us to overcome them and lead to a more secure, robust, and performant post-quantum web.
The draft is X25519Kyber768, which is a combination of the pre-quantum algorithm X25519, and the post-quantum algorithm Kyber 768. Kyber is being renamed to ML-KEM, however for the purposes of this post, we will use “Kyber” to refer to the hybrid algorithm defined for TLS. ↩
As the standards from NIST and IETF are not yet complete, this will be later removed and replaced with the final versions. At this stage of standardization, we expect only early adopters to use the primitives. ↩
It actually exists in considerably more than two forms, but from an organizational perspective, there are versions that signed by other Let’s Encrypt certificates, and a version that is signed by IdenTrust, which is a completely separate certification authority from Let’s Encrypt. ↩
The chain length includes the root certificate and leaf certificate. The byte numbers are what is transmitted over the wire, and so they include the leaf certificate but not the root certificate. ↩
Posted by David Adrian, Bob Beck, David Benjamin and Devon O'Brien
Used billions of times each day, the Chrome address bar (which we call the “omnibox”) is a powerful tool to make searching the web easier, whether you’re trying to quickly find your tabs or bookmarks, return to a web page you previously visited, or find information.
With the latest release of Chrome (M124), we’re integrating machine learning models to power the Chrome omnibox on desktop, so that web page suggestions are more precise and relevant to you. In the future, these models will also help improve the relevance scoring of search suggestions. Here’s a closer look at some of the important insights that help our team build this integration and where we hope the new model takes us.
As the engineering lead for the team responsible for the omnibox, every launch feels special, but this one is truly near and dear to my heart. When I first started working on the Chrome omnibox, I asked around for ideas on how we could make it better for users. The number one answer I heard was, "improve the scoring system." The issue wasn't that the scoring was bad. In fact, the omnibox often feels magical in its ability to surface the URL or query you want! The issue was that it was inflexible. A set of hand-built and hand-tuned formulas did the job well, but were difficult to improve or to adapt to new scenarios. As a result, the scoring system went largely untouched for a long time.
For most of that time, an ML-trained scoring model was the obvious path forward. But it took many false starts to finally get here. Our inability to tackle this challenge for so long was due to the difficulty of replacing the core mechanism of a feature used literally billions of times every day. Software engineering projects are sometimes described as "building the plane while flying it." This project felt more like "replacing all the seats in every plane in the world while they're all flying." The scale was enormous and the changes are felt directly by every user.
This ambitious undertaking would not have been possible without the work of such a talented and dedicated team. There were bumps in the road, walls we had to break through, and unanticipated issues that slowed us down, but the team was driven by a sincere belief in the impact of getting this right for our users.
One of the fun things about working with ML systems is that the training considers all the data at a scale that would be difficult to impossible for any individual person or team. And that can lead to surprising insights.
The coolest example of this phenomenon on this project was when we looked at the scoring curve of one particular signal: time since last navigation. The expectation with this signal is that the smaller it is (the more recently you've navigated to a particular URL), the bigger the contribution that signal should make towards a higher relevance score.
And that is, in fact, what the model learned. But when we looked closer, we noticed something surprising: when the time since navigation was very low (seconds instead of hours, days or weeks), the model was decreasing the relevance score. It turns out that the training data reflected a pattern where users sometimes navigate to a URL that was not what they really wanted and then immediately return to the Chrome omnibox and try again. In that case, the URL they just navigated to is almost certainly not what they want, so it should receive a low relevance score during this second attempt.
In retrospect, this is obvious. And if we had not launched ML scoring, we definitely would have added a new rule to the old system to reflect this scenario. But before the training system observed and learned from this pattern, it never occurred to anyone that this might be happening.
With the new ML models, we believe this will open up many new possibilities to improve the user experience by potentially incorporating new signals, like differentiating between time of the day to improve relevance. We want to explore training specialized versions of the model for particular environments: for example, mobile, enterprise or academic users, or perhaps different locales.
Additionally, we observe that the way users interact with the Chrome omnibox changes over time and we believe the relevance scoring should change with them. With the new scoring system, we can now simply collect fresher signals, re-train, evaluate, and deploy new models periodically over time.
By Justin Donnelly, Chrome software engineer
Cookies – small files created by sites you visit – are fundamental to the modern web. They make your online experience easier by saving browsing information, so that sites can do things like keep you signed in and remember your site preferences. Due to their powerful utility, cookies are also a lucrative target for attackers.
Many users across the web are victimized by cookie theft malware that gives attackers access to their web accounts. Operators of Malware-as-a-Service (MaaS) frequently use social engineering to spread cookie theft malware. These operators even convince users to bypass multiple warnings in order to land the malware on their device. The malware then typically exfiltrates all authentication cookies from browsers on the device to remote servers, enabling the attackers to curate and sell the compromised accounts. Cookie theft like this happens after login, so it bypasses two-factor authentication and any other login-time reputation checks. It’s also difficult to mitigate via anti-virus software since the stolen cookies continue to work even after the malware is detected and removed. And because of the way cookies and operating systems interact, primarily on desktop operating systems, Chrome and other browsers cannot protect them against malware that has the same level of access as the browser itself.
To address this problem, we’re prototyping a new web capability called Device Bound Session Credentials (DBSC) that will help keep users more secure against cookie theft. The project is being developed in the open at github.com/WICG/dbsc with the goal of becoming an open web standard.
By binding authentication sessions to the device, DBSC aims to disrupt the cookie theft industry since exfiltrating these cookies will no longer have any value. We think this will substantially reduce the success rate of cookie theft malware. Attackers would be forced to act locally on the device, which makes on-device detection and cleanup more effective, both for anti-virus software as well as for enterprise managed devices.
Learning from prior work, our goal is to build a technical solution that’s practical to deploy to all sites large and small, to foster industry support to ensure broad adoption, and to maintain user privacy.
At a high level, the DBSC API lets a server start a new session with a specific browser on a device. When the browser starts a new session, it creates a new public/private key pair locally on the device, and uses the operating system to safely store the private key in a way that makes it hard to export. Chrome will use facilities such as Trusted Platform Modules (TPMs) for key protection, which are becoming more commonplace and are required for Windows 11, and we are looking at supporting software-isolated solutions as well.
The API allows a server to associate a session with this public key, as a replacement or an augmentation to existing cookies, and verify proof-of-possession of the private key throughout the session lifetime. To make this feasible from a latency standpoint and to aid migrations of existing cookie-based solutions, DBSC uses these keys to maintain the freshness of short-lived cookies through a dedicated DBSC-defined endpoint on the website. This happens out-of-band from regular web traffic, reducing the changes needed to legacy websites and apps. This ensures the session is still on the same device, enforcing it at regular intervals set by the server. For current implementation details please see the public explainer.
Each session is backed by a unique key and DBSC does not enable sites to correlate keys from different sessions on the same device, to ensure there's no persistent user tracking added. The user can delete the created keys at any time by deleting site data in Chrome settings. The out-of-band refresh of short-term cookies is only performed if a user is actively using the session (e.g. browsing the website).
DBSC doesn’t leak any meaningful information about the device beyond the fact that the browser thinks it can offer some type of secure storage. The only information sent to the server is the per-session public key which the server uses to certify proof of key possession later.
We expect Chrome will initially support DBSC for roughly half of desktop users, based on the current hardware capabilities of users' machines. We are committed to developing this standard in a way that ensures it will not be abused to segment users based on client hardware. For example, we may consider supporting software keys for all users regardless of hardware capabilities. This would ensure that DBSC will not let servers differentiate between users based on hardware features or device state (i.e. if a device is Play Protect certified or not).
DBSC will be fully aligned with the phase-out of third-party cookies in Chrome. In third-party contexts, DBSC will have the same availability and/or segmentation that third-party cookies will, as set by user preferences and other factors. This is to make sure that DBSC does not become a new tracking vector once third-party cookies are phased out, while also ensuring that such cookies can be fully protected in the meantime. If the user completely opts out of cookies, third-party cookies, or cookies for a specific site, this will disable DBSC in those scenarios as well.
We are currently experimenting with a DBSC prototype to protect some Google Account users running Chrome Beta. This is an early initiative to gauge the reliability, feasibility, and the latency of the protocol on a complex site, while also providing meaningful protection to our users. When it’s deployed fully, consumers and enterprise users will get upgraded security for their Google accounts under the hood automatically. We are also working to enable this technology for our Google Workspace and Google Cloud customers to provide another layer of account security.
This prototype is integrated with the way Chrome and Google Accounts work together, but is validating and informing all aspects of the public API we want to build.
Many server providers, identity providers (IdPs) such as Okta, and browsers such as Microsoft Edge have expressed interest in DBSC as they want to secure their users against cookie theft. We are engaging with all interested parties to make sure we can present a standard that works for different kinds of websites in a privacy preserving way.
Development happens on GitHub and we have published an estimated timeline. This is where we will post announcements and updates to the expected timelines as needed. Our goal is to allow origin trials for all interested websites by the end of 2024. Please reach out if you'd like to get involved. We welcome feedback from all sources, either by opening a new issue or starting a discussion on GitHub.
Today’s The Fast and the Curious post covers the release of Speedometer 3.0 an upgraded browser benchmarking tool to optimize the performance of Web applications.
In collaboration with major web browser engines, Blink/V8, Gecko/SpiderMonkey, and WebKit/JavaScriptCore, we’re excited to release Speedometer 3.0. Benchmarks, like Speedometer, are tools that can help browser vendors find opportunities to improve performance. Ideally, they simulate functionality that users encounter on typical websites, to ensure browsers can optimize areas that are beneficial to users.
Let’s dig into the new changes in Speedometer 3.0.
Since its initial release in 2014 by the WebKit team, browser vendors have successfully used Speedometer to optimize their engines and improve user experiences on the web. Speedometer 2.0, a result of a collaboration between Apple and Chrome, followed in 2018, and it included an updated set of workloads that were more representative of the modern web at that time.
The web has changed a lot since 2018, and so has Speedometer in its latest release, Speedometer 3. This work has been based on a joint multi-stakeholder governance model to share work, and build a collaborative understanding of performance on the web to help drive browser performance in ways that help users. The goal of this collaborative project is to create a shared understanding of web performance so that improvements can be made to enhance the user experience. Together, we were able to to improve how Speedometer captures and calculates scores, show more detailed results and introduce an even wider variety of workloads. This cross-browser collaboration introduced more diverse perspectives that enabled clearer insights into a broader set of web users and workflows, ensuring the newest version of Speedometer will help make the web better for everyone, regardless of which browser they use.
Building a reliable benchmark with representative tests and workloads is challenging enough. That task becomes even more challenging if it will be used as a tool to guide optimization of browser engines over multiple years. To develop the Speedometer 3 benchmark, the Chrome Aurora team, together with colleagues from other participating browser vendors, were tasked with finding new workloads that accurately reflect what users experience across the vast, diverse and eclectic web of 2024 and beyond.
A few tests and workloads can’t simulate the entire web, but while building Speedometer 3 we have established some criteria for selecting ones that are critical to user’s experience. We are now closer to a representative benchmark than ever before. Let’s take a look at how Speedometer workloads evolved
Since the goal is to use workloads that are representative of the web today, we needed to take a look at the previous workloads used in Speedometer and determine what changes were necessary. We needed to decide which frameworks are still relevant, which apps needed updating and what types of work we didn’t capture in previous versions. In Speedometer 2, all workloads were variations of a todo app implemented in different JS frameworks. We found that, as the web evolved over the past six years, we missed out on various JavaScript and Browser APIs that became popular, and apps tend to be much larger and more complicated than before. As a result, we made changes to the list of frameworks we included and we added a wider variety of workloads that cover a broader range of APIs and features.
To determine which frameworks to include, we used data from HTTP Archive and discussed inclusion with all browser vendors to ensure we cover a good range of implementations. For the initial evaluation, we took a snapshot of the HTTP Archive from March 2023 to determine the top JavaScript UI frameworks currently used to build complex web apps.
Another approach is to determine inclusion based on popularity with developers: Do we need to include frameworks that have “momentum”, where a framework's current usage in production might be low, but we anticipate growth in adoption? This is somewhat hard to determine and might not be the ideal sole indicator for inclusion. One data point to evaluate momentum might be monthly NPM downloads of frameworks.
Here are the same 15 frameworks NPM downloads for March 2023:
With both data points on hand, we decided on a list that we felt gives us a good representation of frameworks. We kept the list small to allow space for brand new types of workloads, instead of just todo apps. We also selected commonly used versions for each framework, based on the current usage.
In addition, we updated the previous JavaScript implementations and included a new web-component based version, implemented with vanilla JavaScript.
A simple Todo-list only tests a subset of functionality. For example: how well do browsers handle complicated flexbox and grid layouts? How can we capture SVG and canvas rendering and how can we include more realistic scenarios that happen on a website?
We collected and categorized areas of interest into DOM, layout, API and patterns, to be able to match them to potential workloads that would allow us to test these areas. In addition we collected user journeys that included the different categories of interest: editing text, rendering charts, navigating a site, and so on.
There are many more areas that we weren’t able to include, but the final list of workloads presents a larger variety and we hope that future versions of Speedometer will build upon the current list.
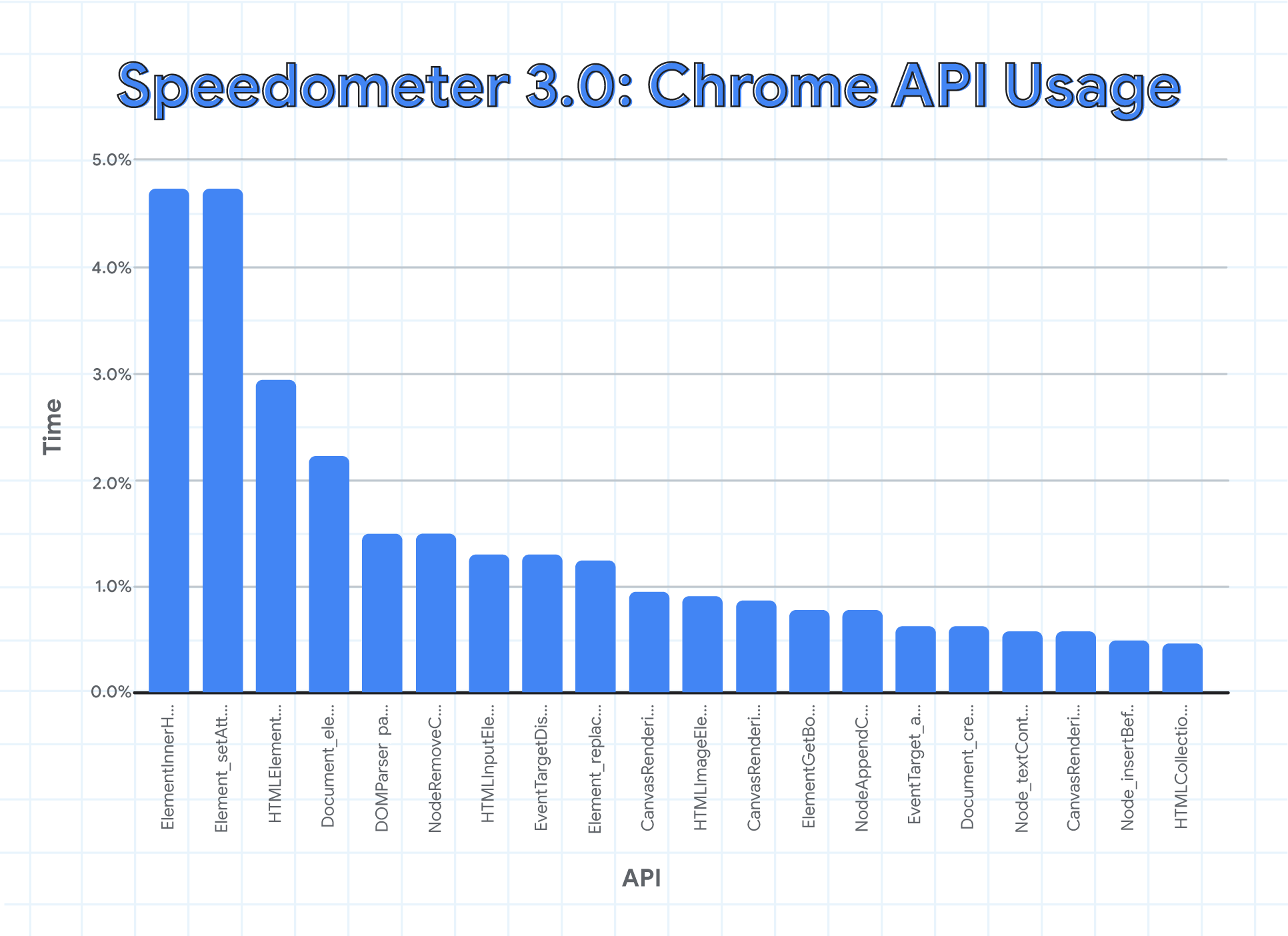
The Chrome Aurora team worked with the Chrome V8 team to validate our assumptions above. In Chrome, we can use runtime-call-stats to measure time spent in each web API (and additionally many internal components). This allows us to get an insight into how dominant certain APIs are.
If we look at Speedometer 2.1 we see that a disproportionate amount of benchmark time is spent in innerHTML.
While innerHTML is an important web API, it's overrepresented in Speedometer 2.1. Doing the same analysis on the new version 3.0 yields a slightly different picture:
We can see that innerHTML is still present, but its overall contribution shrunk from roughly 14% down to 4.5%. As a result, we get a better distribution that favors more DOM APIs to be optimized. We can also see that a few Canvas APIs have moved into this list, thanks to the new workloads in v3.0.
While we will never be able to perfectly represent the whole web in a fast-running and stable benchmark, it is clear that Speedometer 3.0 is a giant step in the right direction.
Ultimately, we ended up with the following list of workloads presented in the next few sections.
TodoMVC
Many developers might recognize the TodoMVC app. It’s a popular resource for learning and offers a wide range of TodoMVC implementations with different frameworks.
TodoMVC is a to-do application that allows a user to keep track of tasks. The user can enter a new task, update an existing one, mark a task as completed, or delete it. In addition to the basic CRUD operations, the TodoMVC app has some added functionality: filters are available to change the view to “all”, “active” or “completed” tasks and a status text displays the number of active tasks to complete.
In Speedometer, we introduced a local data source for todo items, which we use in our tests to populate the todo apps. This gave us the opportunity to test a larger character set with different languages.
The tests for these apps are all similar and are relatable to typical user journeys with a todo app:
These tests seem simple, but it lets us benchmark DOM manipulations. Having a variety of framework implementations also cover several different ways how this can be done.
Complex DOM / TodoMVC
The complex DOM workloads embed various TodoMVC implementations in a static UI shell that mimics a complex web page. The idea is to capture the performance impact on executing seemingly isolated actions (e.g. adding/deleting todo items) in the context of a complex website. Small performance hits that aren’t obvious in an isolated TodoMVC workload are amplified in a larger application and therefore capture more real-world impact.
The tests are similar to the TodoMVC tests, executed in the complex DOM & CSSOM environment.
This introduces an additional layer of complexity that browsers have to be able to handle effortlessly.
Single-page-applications (News Site)
Single-page-applications (SPAs) are widely used on the web for streaming, gaming, social media and pretty much anything you can imagine. A SPA lets us capture navigating between pages and interacting with an app. We chose a news site to represent a SPA, since it allows us to capture the main areas of interest in a deterministic way. An important factor was that we want to ensure we are using static local data and that the app doesn’t rely on network requests to present this data to the user.
Two implementations are included: one built with Next.js and the other with Nuxt. This gave us the opportunity to represent applications built with meta frameworks, with the caveat that we needed to ensure to use static outputs.
Tests for the news site mimic a typical user journey, by selecting a menu item and navigating to another section of the site.
These tests let us evaluate how well a browser can handle large DOM and CSSOM changes, by changing a large amount of data that needs to be displayed when navigating to a different page.
Charting Apps & Dashboards
Charting apps allow us to test SVG and canvas rendering by displaying charts in various workloads.
These apps represent popular sites that display financial information, stock charts or dashboards.
Both SVG rendering and the use of the canvas api weren’t represented in previous releases of Speedometer.
Observable Plot displays a stacked bar chart, as well as a dotted chart. It is based on D3, which is a JavaScript library for visualizing tabular data and outputs SVG elements. It loops through a big dataset to build the source data that D3 needs, using map, filter and flatMap methods. As a result this exercises creation and copying of objects and arrays.
Chart.js is a JavaScript charting library. The included workload displays a scatter graph with the canvas api, both with some transparency and with full opacity. This uses the same data as the previous workload, but with a different preparation phase. In this case it makes a heavy use of trigonometry to compute distances between airports.
React Stockcharts displays a dashboard for stocks. It is based on D3 for all computation, but outputs SVG directly using React.
Webkit Perf-Dashboard is an application used to track various performance metrics of WebKit. The dashboard uses canvas drawing and web components for its ui.
These workloads test DOM manipulation with SVG or canvas by interacting with charts. For example here are the interactions of the Observable Plot workload:
Code Editors
Editors, for example WYSIWYG text and code editors, let us focus on editing live text and capturing form interactions. Typical scenarios are writing an email, logging into a website or filling out an online form. Although there is some form interaction present in the TodoMVC apps, the editor workloads use a large data set, which lets us evaluate performance more accurately.
Codemirror is a code editor that implements a text input field with support for many editing features. Several languages and frameworks are available and for this workload we used the JavaScript library from Codemirror.
Tiptap Editor is a headless, framework-agnostic rich text editor that's customizable and extendable. This workload used Tiptap as its basis and added a simple ui to interact with.
Both apps test DOM insertion and manipulation of a large amount of data in the following way:
Being able to collaborate with all major browser vendors and having all of us contribute to workloads has been a unique experience and we are looking forward to continuing to collaborate in the browser benchmarking space.
Don’t forget to check out the new release of Speedometer and test it out in your favorite browser, dig into the results, check out our repo and feel free to open issues with any improvements or ideas for workloads you would like to see included in the next version. We are aiming for a more frequent release schedule in the future and if you are a framework author and want to contribute, feel free to file an issue on our Github to start the discussion.
Posted by Thorsten Kober, Chrome Aurora


















.png)





